원문: Automatic Exposure Using a Luminance Histogram 밝기 히스토그램을 사용한 자동 노출
들어가며
최근 연습삼아 크로스 플랫폼 렌더링 라이브러리인 bgfx를 사용한 렌더러를 만들었습니다. 이 렌더러는 glTF 모델을 불러와 glTF 스펙에 설명된 쿡-토랜스 모델에 따라 그립니다. 구현을 다 마치지는 않았고 단순히 점조명을 이용해 머티리얼을 그릴 뿐입니다. 셰이더는 정점+프래그먼트 셰이더뿐입니다. FlightHelmet 모델을 불러오고 왼쪽 오른쪽에 각각 조명을 놓고 프로그램을 실행하면 아래 그림과 같습니다:

사진에서 보이듯이 밝아지는 부분은 단순히 광원의 색깔만 있고 노멀 맵과 알베도 텍스쳐에서 나올 것으로 기대한 모든 디테일이 못생긴 얼룩들로 지워졌습니다. 이건 제가 기대했던 부분이 아니었습니다. 이게 왜 버그가 아니고 왜 프래그먼트 셰이더가 이런 이상한 이미지를 주는지는 분명하지 않을 수 있기 때문에 재빨리 설명하겠습니다. 일단 최종 이미지가 어떻게 나와야 할 지 톤 매핑한 같은 씬을 보여드리겠습니다:

물리 기반 라이팅
물리 기반 라이팅에서는 물체들을 복사측정술이나 측광에서 사용되는 물리 기반 단위들을 사용하여 그립니다. 렌더링 공식에서는 각 픽셀이 내는 빛을 계산합니다. 위의 예제에서 조명은 루멘이라는 광학 단위를 사용하는데, 각각 800lm으로 설정되었고 더 크게 할 수도 있습니다. 방향성 조명으로 볼 수 있는 태양은 지구 표면을 ~120,000lux로 비춥니다. 그 말인즉슨 이 물체들의 렌더링 공식을 풀 때 사실상 상한이 없는 값들을 만나게 되고 같은 프레임에도 몇몇 규모에 따라 다른 광량값을 보게 될 것이라는 점입니다. 그에 더해, 이런 모든 계산들은 선형 공간에서 이루어지고 있다는 점입니다. 쉽게 말하면, (1.0, 1.0, 1.0)의 RGB값은 (2.0, 2.0, 2.0)이라는 더 큰 광량의 절반을 뜻합니다.
또다른 문제는 우리가 갖고 있는 대부분의 디스플레이들이 다르게 동작한다는 점입니다. 표준 정의 디스플레이는 프레임 버퍼에 (1.0, 1.0, 1.0)이 흰색인, 0과 1 사이의 sRGB 색공간의 RGB값이 들어가 있기를 기대합니다. 따라서 프래그먼트 셰이더가 만드는 어떤 값이든지 32비트 백버퍼에 기록될 때 [0, 1] 범위로 클리핑됩니다. 결국 우리는 클리핑된 색상들을 내게 되어 거의 흰색으로만 된 화면이 나오데 됩니다!
톤 매핑
해결방법은 물리적으로 제한되지 않은 HDR 값들을 LDR 선형 공간인 [0, 1]로 매핑하고 마지막에 감마 보정을 통해 디스플레이가 원하는 sRGB값을 만들어 내는 것입니다. 아래 그림이 가장 단순한 톤 매핑 파이프라인을 설명해줍니다:
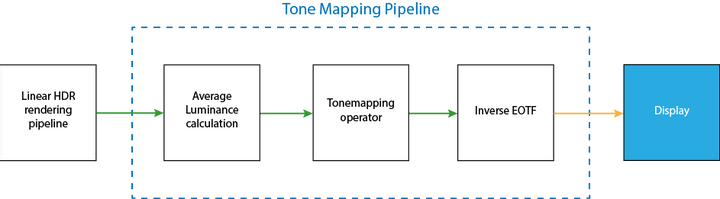
이 파이프라인은 다섯 단계로 되어 있습니다:
- 씬을 HDR 값을 지원하는 프레임버퍼에(예를 들어 채널당 16비트 또는 32비트 부동소수점 버퍼) 그립니다. 어떤 프레임버퍼를 사용하느냐에 대한 선택은 (언제나) 정밀도와 범위, 메모리 간의 트레이드오프입니다. 여기에서는 RGBA16F 프레임 버퍼를 사용할 것입니다. 출력이 선형 공간인지 확인해야 합니다.
- 밉맵이나 컴퓨팅 셰이더를 사용하여 HDR 색상 버퍼에서 평균 씬 조도를 찾습니다.
- 독립된 렌더 피스에서 선형이고 클램핑된 색상 버퍼를 생성합니다:
- 평균 씬 조도를 사용하여 입력을 스케일하여 “측정된” RGB 값을 구합니다.
- 측정된 값을 톤 커브를 사용하여 스케일합니다. 입력으로 RGB 또는 프래그먼트의 조도를 넣습니다.
- 선형 클램핑된 값을 역광전자 전달 함수를(EOTF, inverse electrical optical transfer function) 이용하여 변환합니다.
- 일반적인 비-HDR 디스플레이에는 기본적으로 역 감마 변환을 적용하여 선형 색상을 sRGB 색공간을 바꿉니다.
- 결과로 나온 이 비선형 결과를 백버퍼에 기록하여 유저에게 보여줍니다.
위 그림에서 녹색 화살표는 입출력이 선형 공간임을 의미하고, 오렌지색 화살표는 감마 공간을 의미합니다.
이 포스팅의 나머지에서는 두 번째 단계였던 평균 조도값을 찾는 방법과, 어떻게 이 값으로 입력 조도를 스케일하는지에 대한 내용을 다룰 것입니다. 세 번째 단계는 톤 연산을 다루는 다음 포스팅에서 다룰 것입니다.
우선 노출을 이요하여 입력 조도를 스케일하는 과정에 대해 설명하겠습니다.
노출
사람의 눈은 무엇인가를 볼 때 동공을 자연스럽게 조절하여 눈에 도달하는 빛의 양을 조절합니다. 비슷하게 사진작가들 역시 조리개 크기(f-stop) 또는 셔터 속도와 같이 센서에 도달하는 빛의 양을 조절하는 몇 가지 방법을 가지고 있습니다. 사진술에서 이러한 조작들은 EV라고도 하는 노출값과 관련이 있는데, EV는 조도를 로그로 표시한 값입니다. EV를 +1만큼 올리면 조도를 두배로 올리는 것과 같습니다.
노출은 우리의 관점에서 봤을 때 씬의 조도를 선형적으로 스케일하여 실제로 얼마나 많은 빛이 센서를 때리는지 시뮬레이션합니다. 이렇게 하는 이유는 입력 화면을 톤 오퍼레이터가 우리가 기대하는 값으로 스케일하는 도메인으로 바꾸기 위해서입니다. 카메라와 비교하여 어떻게 이것이 동작하는지 이해하는 데에는 꽤 시간이 걸렸지만, 사실 기본적으로는 같은 개념입니다. 실제 카메라에서 센서를 때리는 광자들의 양은 피사체를 잘 보이게 하기 위해 너무 많은 빛도 아니고 너무 적은 빛도 되지 않도록 조절되어야 합니다.
실제로 노출값을 정하는 것은 우리에게 달려 있지만 사용자나 아티스트가 직접 건드리지 않게 하기 위해서 HDR 버퍼에서 씬의 평균 조도를 구해 노출값을 계산할 것입니다. 들어가기에 앞서 조도를 RGB 색상의 함수로 정의하는 것이 좋겠습니다:
L = 0.2125R + 0.7154G + 0.0721B
여기서 R, G, B는 HDR 버퍼에 저장된 각각의 방출량 값에 해당합니다. CIE xyY 색공간의 일부이며, 계수들은 빨간색, 녹색, 파란색 각각 해당하는 휘도 함수에서 가져온 것입니다.
실제로 평균 씬 조도에서 노출값을 계산하는 몇 가지 방법이 있는데, Krzysztof Narkowicz의 포스팅에 대부분이 설명되어 있으므로 참고하실 수 있습니다. 이 포스팅에서는 Lagard and de Rousiers, 2014(85페이지)에 설명된 방법을 사용하겠습니다. 기본적으로 센서를 포화시키는 조도값인 L_max를 계산할 수 있고, 그리고 나서 씬 조도를 스케일합니다.
EV_100 = log_2 (L_avg(S/K)) L_max = 78/qS x 2^(EV_100) H = 1 / L_max
여기서 S는 센서 민감도이고, K는 반사광 미터 측정 상수이며, q는 렌즈 및 비네팅 감쇠이고, H가 노출이며 L_avg가 평균 씬 조도입니다.
우리가 실제 카메라를 흉내낸다면 뎁스 오브 필드에 영향을 미치는 조리개 크기를 바꿀 때 잃는 빛의 양을 오프셋하기 위해 다른 S값을 사용해야 할 수도 있습니다. 하지만 그부분은 신경쓰지 않을 것이기 때문에 S=100으로 합니다. 그리고 캐논이나 니콘, 세코닉 모두 K=12.5를 사용하는 것으로 보이며 대부분의 렌더링 엔진도 이를 따라갑니다. 마지막으로 q=0.65가 대부분 사용됩니다. 만약 어떤 계수들이 실제로 어떻게 동작하는지 아는 데 관심이 있다면 Lagard and de Rousiers, 2014나 Filament에 자세한 설명이 있습니다.
우리 방정식을 단순화하고 상수들을 대입하여 L_max 공식을 간단히 다시 써 보면 이렇습니다:
L_max = 9.6 x L_avg
그렇다면 스케일링된 최종 조도는 이렇게 됩니다:
L’ = H x L = c_rgb / L_max = L / (9.6 x L_avg)
이 값은 여전히 [0, 1] 범위로 클램핑되지 않았기 때문에 잠재적으로 많은 클리핑이 일어날 수 있습니다.
그리고 아직 평균 조도를 계산하는 방법에 대해서도 다루지 않았습니다. 두 가지 유명한 방법이 있습니다: - HDR 이미지를 반복적으로 다운샘플링한 기하 평균을 사용한다(밉맵 체인과 비슷). - 정적 조도 범위의 히스토그램을 생성한다.
기하 평균을 사용한 방법은 극단적인 값에 민감하게 반응하여 최종 조도 값을 과도하게 바꾸기 때문에 기하 평균 대신 히스토그램을 만드는 방향으로 갈 것입니다. 이 방법은 (원한다면) 극단적인 값이 “평균”에 얼만큼 영향을 미칠지 더 많은 제어권을 제공합니다. 히스토그램을 사용하면 필요한 경우 중앙값과 같은 값들도 사용할 수 있습니다. 당장은 평균만 보도록 하겠습니다.
조도 히스토그램 구성하기
여기서는 히스토그램을 만들기 위해 같은 내용을 다룬 Alex Tardif의 블로그 포스팅을 레퍼런스로 사용하였습니다. 여기 나온 코드를 설명드리고, Tardif의 방법을 따라하면서 가장 혼란스러웠던 부분에도 초점을 맞춰 보겠습니다. 아래 코드는 BGFX 버전의 glsl로 쓰인 컴퓨팅 셰이더입니다:
업데이트: 아래 컴퓨트 셰이더 두 개의 버그를 수정했습니다. 전에는 동기화를 위해 groupMemoryBarrier를 사용했지만 실제로는 실행 및 그룹 메모리 배리어로 쓰려고 했기 때문에 적절하지 않았습니다. BGFX의 shaderc가 실제로 GLSL을 GroupMemoryBarrierWithGroupSync()로 번역하고 있고 DX11 백엔드로만 샘플을 돌릴 수 있기 때문에 실제로 이슈가 있었던 적은 없었습니다. 버그를 발견하고 솔루션을 알려준 그래픽스 프로그래밍 디스코드의 Cirdan과 marttyfication에게 감사드립니다.
// 아래 구문으로 gl_LocalInvocationIndex를 HLSL의 SV_GroupIndex로
// 번역하는 것과 같은 모든 정의들과 번역과 관련된 것들을 추가합니다
#include <bgfx_compute.sh>
#define GROUP_SIZE 256
#define THREADS_X 16
#define THREADS_Y 16
#define EPSILON 0.005
// Taken from RTR vol 4 pg. 278
#define RGB_TO_LUM vec3(0.2125, 0.7154, 0.0721)
// 유니폼:
uniform vec4 u_params;
// u_params.x = 최소 log_2 조도
// u_params.y = log_2 조도 범위의 역수
// 읽기 전용 HDR 색상 이미지와 히스토그램 버퍼, 총 두 개의 입력입니다
IMAGE2D_RO(s_texColor, rgba16f, 0);
BUFFER_RW(histogram, uint, 1);
// 각 워크 그룹별로 일시적으로 합계를 저장하는 데 사용하는 공유 히스토그램 버퍼입니다
SHARED uint histogramShared[GROUP_SIZE];
// 주어진 색상과 조도 범위에서 히스토그램 빈 인덱스를 반환합니다
uint colorToBin(vec3 hdrColor, float minLogLum, float inverseLogLumRange) {
// RGB값을 조도로 변환합니다. 위 RGB_TO_LUM 매크로의 주석을 참고
float lum = dot(hdrColor, RGB_TO_LUM);
// 0에 로그를 취하는 것은 예외
if (lum < EPSILON) {
return 0;
}
// log_2 조도를 계산하고 값을 [0.0, 1.0] 범위로 표현합니다
// 0.0은 최소 조도이며 1.0은 최대 조도입니다
float logLum = clamp((log2(lum) - minLogLum) * inverseLogLumRange, 0.0, 1.0);
// [0, 1] 범위를 [1, 255]로 확장합니다. 첫번째 빈은 위의 epsilon 체크에서 처리됐습니다.
return uint(logLum * 254.0 + 1.0);
}
// 그룹당 16 * 16 * 1 스레드를 사용
NUM_THREADS(THREADS_X, THREADS_Y, 1)
void main() {
// 이 스레드의 빈 값을 0으로 초기화
histogramShared[gl_LocalInvocationIndex] = 0;
barrier();
uvec2 dim = imageSize(s_texColor).xy;
// HDR 이미지 범위를 넘어가는 매핑을 하는 스레드는 무시합니다
if (gl_GlobalInvocationID.x < dim.x && gl_GlobalInvocationID.y < dim.y) {
vec3 hdrColor = imageLoad(s_texColor, ivec2(gl_GlobalInvocationID.xy)).xyz;
uint binIndex = colorToBin(hdrColor, u_params.x, u_params.y);
// 원자성 덧셈 연산을 통해 서로 다른 스레드에서 동시에 히스토그램의 같은 빈에
// 쓰지 않는다는 걸 확신할 수 있습니다.
atomicAdd(histogramShared[binIndex], 1);
}
// 로컬 히스토그램을 글로벌 히스토그램에 더하기 직전에
// 여기서 워크 그룹의 모든 스레드를 기다립니다
barrier();
// 기술적으로 두 스레드가 같은 빈에 쓸 기회가 없지만
// 다른 워크 그룹은 가능할 수 있습니다! 그렇기 때문에 여전히 원자적 덧셈을 해야 합니다.
atomicAdd(histogram[gl_LocalInvocationIndex], histogramShared[gl_LocalInvocationIndex]);
}
이 컴퓨팅 셰이더는 256(NUM_THREADS) 스레드로 된 워크 그룹을 생성하여 16*16 픽셀 청크 단위로 HDR 입력 이미지에 동작합니다. 각 스레드는 한번에 하나의 픽셀에 동작하는데, 픽셀의 조도값을 사용하여 빈의 인덱스를 할당하고 해당 빈의 카운트를 1 증가시킵니다. NUM_THREADS 값은 256개의 빈을 가진 히스토그램 버퍼에 접근하기 용이하도록 gl_LocalInvocationIndex가 0-255 범위에서 매핑을 수행하기 때문에 선택되었습니다. 아래 그림을 보면 글로벌 워크 그룹과 개별 호출들이 어떻게 동작하는지 이해하는 데 도움이 될 수 있습니다:
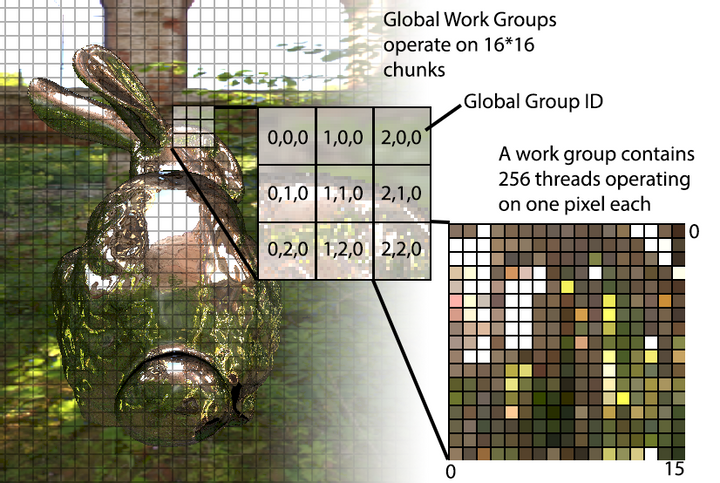
각 워크 그룹은 histogramShared라는 공유 버퍼가 있어서 현재 작업중이 픽셀 청크의 카운트들을 저장합니다. 그리고 나서 마지막에 이 로컬 결과들은 글로벌 histogram 버퍼에 더해집니다. 이런 방식으로 모든 픽셀 작업마다 글로벌 버퍼에 락을 거는 오버헤드를 피할 수 있습니다.
각 워크 그룹마다 중간 결과를 저장하기 위해 histogramShared 공유 버퍼를 사용하고 각 호출의 마지막에만 글로벌 histogram 버퍼에 결과들을 집계한다는 점이 중요합니다.
전체 이미지를 다룰 수 있을 정도로 워크 그룹 크기를 크게 하고 컴퓨팅 셰이더를 돌리고 나면, 입력 버퍼에는 히스토그램 데이터가 다 들어가 있을 것입니다.
평균 계산하기
조도 버퍼를 구했으니 이제 평균을 구할 수 있습니다. 버퍼가 GPU 안에 있기 때문에 다른 컴퓨팅 셰이더를 사용하여 평균을 구할 수 있습니다. 이번에는 계산 공간이 2D 이미지가 아니라 1D 히스토그램이 됩니다. 덧붙여 버퍼에 기록하는 대신 버퍼에서 읽어들여 계산된 값을 픽셀 하나짜리 R16F 텍스쳐에 저장할 것입니다. 그렇기 때문에 방금 전 프로그램보다 더 단순하게 나올 겁니다. Alex Tardif의 내용에 따르면 컴퓨팅 셰이더는 아래와 같습니다:
#include "bgfx_compute.sh"
#define GROUP_SIZE 256
#define THREADS_X 256
#define THREADS_Y 1
// 유니폼:
uniform vec4 u_params;
#define minLogLum u_params.x
#define logLumRange u_params.y
#define timeCoeff u_params.z
#define numPixels u_params.w
#define localIndex gl_LocalInvocationIndex
// s_target에 평균값을 기록할 겁니다
IMAGE2D_RW(s_target, r16f, 0);
BUFFER_RW(histogram, uint, 1);
// 공유
SHARED uint histogramShared[GROUP_SIZE];
NUM_THREADS(THREADS_X, THREADS_Y, 1)
void main() {
// 히스토그램 버퍼에서 카운트를 가져옵니다
uint countForThisBin = histogram[localIndex];
histogramShared[localIndex] = countForThisBin * localIndex;
barrier();
// 다음 패스를 위해 버퍼에 저장된 카운트를 리셋합니다
histogram[localIndex] = 0;
// 이 루프에서 조도 범위의 가중된 카운트를 계산합니다
UNROLL
for (uint cutoff = (GROUP_SIZE >> 1); cutoff > 0; cutoff >>= 1) {
if (uint(localIndex) < cutoff) {
histogramShared[localIndex] += histogramShared[localIndex + cutoff];
}
barrier();
}
// 아래 부분은 한번만 계산하면 되므로 스레드 하나만 필요합니다.
if (threadIndex == 0) {
// 가중된 합계를 가져와 0보다 조도가 큰 픽셀 수로 나눕니다
// (index == 0이기 때문에 countForThisBin을 통해 검은색 픽셀 수를 알 수 있습니다)
float weightedLogAverage = (histogramShared[0] / max(numPixels - float(countForThisBin), 1.0)) - 1.0;
// 히스토그램 공간을 실제 조도 공간으로 매핑합니다
float weightedAvgLum = exp2(((weightedLogAverage / 254.0) * logLumRange) + minLogLum);
// 새로 저장되는 값은 노출값이 급격하게 변하는 것을 방지하기 위해
// 가장 최근의 프레임 값에서 보간됩니다.
float lumLastFrame = imageLoad(s_target, ivec2(0, 0)).x;
float adaptedLum = lumLastFrame + (weightedAvgLum - lumLastFrame) * timeCoeff;
imageStore(s_target, ivec2(0, 0), vec4(adaptedLum, 0.0, 0.0, 0.0));
}
}
각 스레드마다 히스토그램 값을 읽어 로컬 변수에 저장합니다. 그런 다음 공유 버퍼에 가중된 카운트를 저장합니다. 하는 김에 글로벌 히스토그램 버퍼를 초기화하여 다음 프레임에 사용할 수 있도록 합니다. 또한 이 코드에서 gl_LocalInvocationIndex를 localIndex라는 별명으로 사용했다는 점 참고해주시기 바랍니다.
실제 루프가 무슨 작업을 하는지 명확하지 않을 수 있지만(제게는 명확합니다) 생각보다 간단한 내용입니다. 여기서는 합계를 공유 버퍼의 요소 하나로 집계하고, 컴퓨팅 공간의 병렬성을 활용하여 두 셀의 합들을 한번에 계산합니다.두 셀의 분리는 cutoff = GROUP_SIZE >> 1 = GROUP_SIZE / 2에서 시작되며 distance가 0이 될 때까지 각 이터레이션마다 절반으로 나뉩니다(cutoff >>= 1). gl_LocalInvocationIndex > cutoff인 스레드는 합계에 기여할 수 없기 때문에 중지됩니다. 아래 그림은 인덱스 i인 스레드의 처음 몇 이터레이션을 보여줍니다:
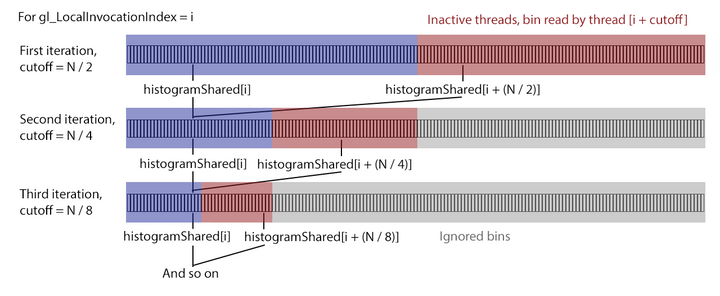
이 다이어그램에서 버퍼의 빨간색 영역은 푸른색 영역과 합쳐져 푸른색 영역에 저장됩니다. 다음 이터레이션에서 빨간색 영역은 (앞으로 있을) 다음 이터레이션에서 사용하지 않을 것이라는 의미에서 회색이 됩니다. 버퍼 크기와 스레드의 크기가 같기 때문에 if (uint(gl_LocalInvocationIndex) < cutoff)에 기반해 사실상 빨간색과 회색에 해당하는 스레드는 중지되어 있는 상태입니다. 오로지 파란색 영역만 활성화되어 있는 것입니다. 효율적이지 않은 것처럼 보일 수 있지만 O(n) 대신 O(log_2(n))의 속도로 집계가 되고 있기 때문에 나이브한 싱글 스레드를 쓰는 것보다는 합리적입니다.
루프의 마지막에서 가중치가 적용된 합계가 나오기 때문에 최종 평균값을 쉽게 구할 수 있습니다. 그렇게 하기 위해서 우선 (위의 집계 시점에 histogramShared[0]에 저장된) 가중 카운트를 나누고 모든 조도에 기여하는 픽셀의 수로 나눕니다. histogram[0]에 저장된 값들은 임계 조도값을 넘지 않는 것이기 때문에 카운트에서 제외합니다.
마지막으로 히스토그램 빈 공간에 히스토그램을 구성할 때 썼던 연산을 역으로 적용하여 실제 조도값으로 돌립니다. 이렇게 하여 해당 프레임의 실제 평균 조도값을 구합니다.
하지만 노출의 급격한 변화가 유저에게 “깜빡이는” 이미지를 줄 수 있기 때문에 이를 방지하기 위해 마지막 프레임의 노출값을 사용하여 좀 더 부드럽게 이미지에 저장되는 값이 바뀌도록 할 것입니다. 이것이 전부입니다! L_avg 값을 구했기 때문에 위의 공식을 활용하여 톤 매핑을 위한 노출값을 계산할 수 있습니다. 그 부분에 대해서는 다음 포스팅에서 다루겠습니다.
샘플 코드
토끼 이미지는 여기에 있는 BGFX 스타일 예제에서 만들었습니다. 화면 구성 및 GPU 리소스와 이미 살펴봤던 셰이더도 있습니다.
'강좌번역' 카테고리의 다른 글
| [번역] 톤 매핑 (2) | 2022.02.11 |
|---|---|
| (번역) Cassandra와 MongoDB 비교 (0) | 2022.02.02 |
| 물리 개체의 PID제어 (0) | 2018.10.17 |
| 그래픽스 API 선택하기 (2) | 2015.09.06 |
